


- DBSCANってなに?
- どんなアルゴリズムなの?
- どんなメリットがある?
- Pythonでどうやって実装するの?
とお悩みではありませんか?
本記事では、DBSCANのアルゴリズムやメリット、Pythonでの実装について解説していきます。
DBSCANは、密度によってクラスタリングを行うため、特殊なデータにも適用できる手法です。
特殊なデータに対しても適用できる点で、クラスタリング手法の中で重宝されています。
本記事の信頼性
この記事を読むことで、DBSCANについてもう悩むことはなくなります!
月額980円で学べる!

データサイエンスの復習は完ぺきにできていますか?
データサイエンスは勉強する範囲が膨大で、復習に手が回りませんよね。
そんなあなたにおすすめなのが、たった月額980円でサクッと学べる『スタアカ』

数分の動画でビジネスへの活用法も含めて、サクッとデータサイエンスを復習可能。
『何冊も参考書を往復して復習する苦労』とはおさらばです!
サブスクなのでいつでも解約OK。手軽に始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも!
それでは本編です!
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)とは
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)は、特殊なデータに対して用いるクラスタリング手法です。
DBSCANは、データの密度が近いものを1つのクラスタとするため、特殊なデータにもクラスタリングを行えます。
例えば、k-means法とDBSCANでのクラスタリングの結果を見比べると特徴が理解できます。
k-means法を詳しく知りたいという方は、『k-means法とは?アルゴリズムやPythonの実装をわかりやすく解説』の記事をご参照ください。

それでは、下図の散布図を見てください。
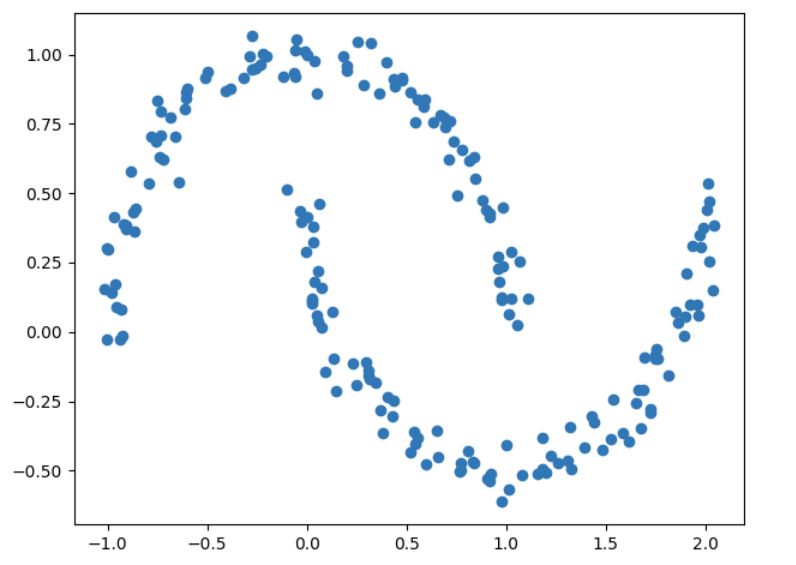
上図の散布図は少し特殊なデータの分布をしています。
そのため、このように特殊な散布図の場合にDBSCANが適しているのです。
以下がk-means法とDBSCANのクラスタリング結果の比較になります。

k-means法は重心からの距離が近い方にクラスタが割り振られるため、中央でクラスタが分かれてしまいます。
一方、DBSCANは密度でクラスタを分けるため、このようなデータの分布であっても正しいクラスタリングを行えるのです。
このように、特殊なデータに対してDBSCANが用いられます。
以下では、DBSCANがどのようなアルゴリズムなのかを解説していきます。
DBSCANのアルゴリズム3ステップ
DBSCANは適当な点を選び、密度で判断しクラスタリングを行う手法です。
以下の3ステップでDBSCANを行えます。
- 適当な点を選択し、その点と一定距離にある点の数を数える
- 点の数がしきい値以上ならクラスタにし、未満ならノイズ点とする
- これまでの操作を点を変えて繰り返す
それぞれのステップについて解説していきます。
STEP1. 適当な点を選択し、その点と一定距離にある点の数を数える
まず、データからランダムに点を選びます。
そして、その点から一定の距離内に存在する他の点の数を数えます。
このとき、定めた一定距離をε(イプシロン)と呼びます。
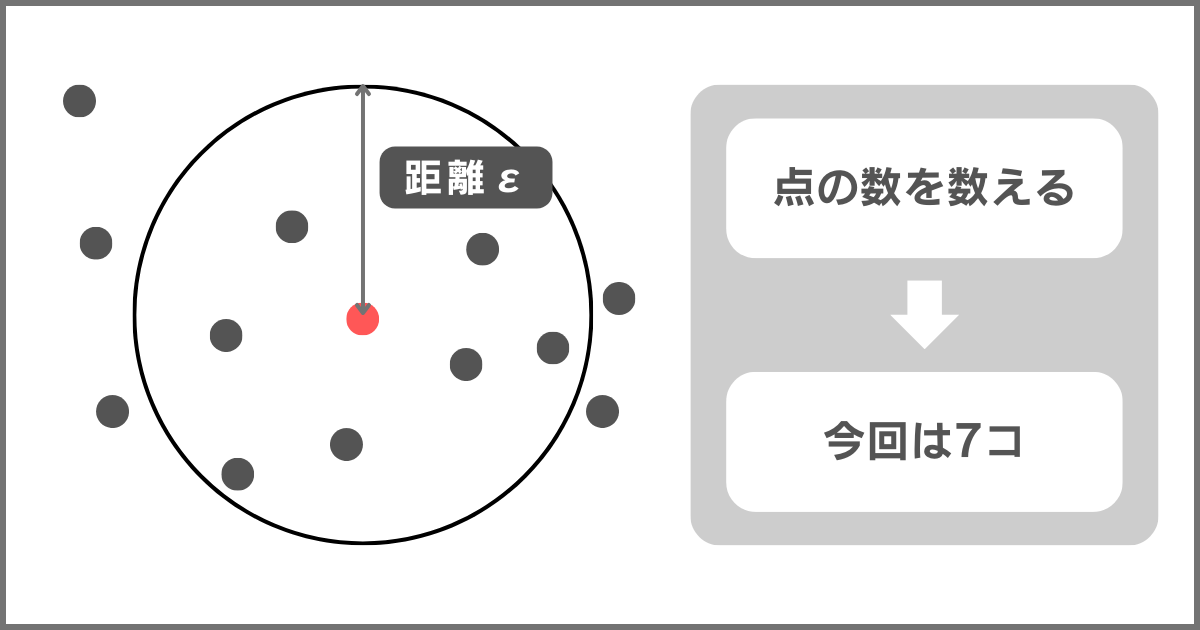
上図のように半径εの円を描き、その円内にある点の数を数えます。
そして、STEP2でクラスタに割り振っていきます。
STEP2. 点の数がしきい値以上ならクラスタにし、未満ならノイズ点とする
これまでに述べた通り、DBSCANは密度からクラスタリングを行う手法になります。
そのため、範囲内の点の数でしきい値を設け、範囲内の点の数がしきい値以上であれば範囲内の点をすべて同じクラスタとみなすのです。
範囲外の点はノイズ点と呼ばれ、同じクラスタでないとみなします。
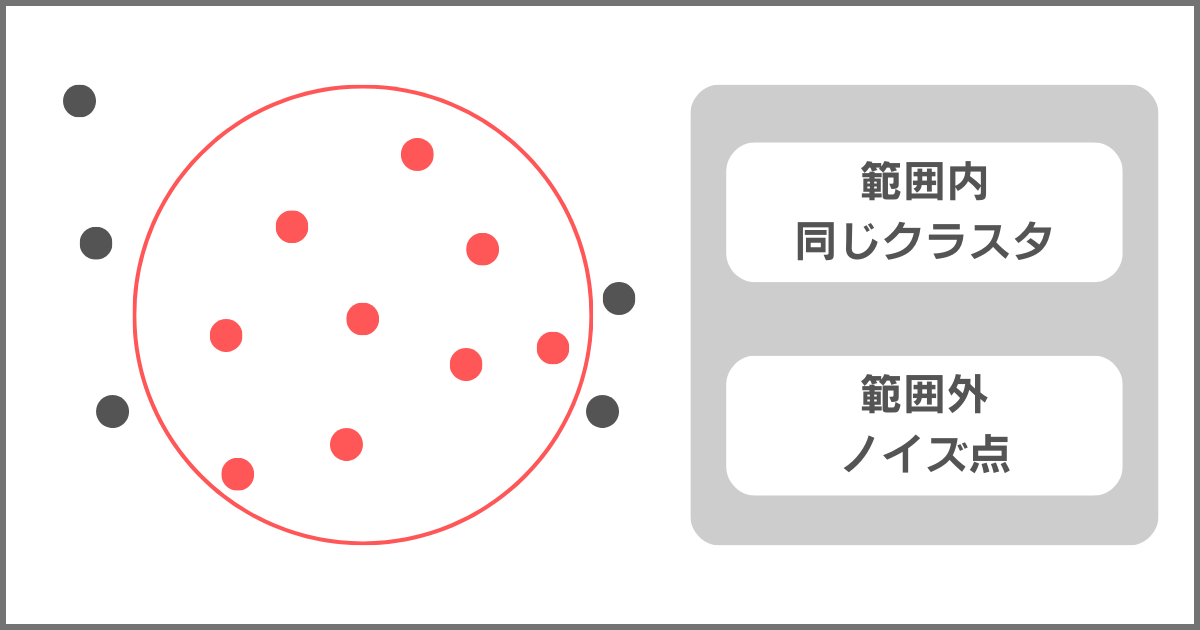
データ点の数がしきい値以上であれば、上図のようにクラスタを割り振ります。
もし、点の数がしきい値未満である場合は、選択した点がノイズ点となるのです。
このように、1つの点を選択して、密度からクラスタを割り振るのがDBSCANの1回のアルゴリズムになります。
STEP3. これまでの操作を点を変えて繰り返す
これまで解説してきたのは、1回のクラスタの割り振りです。
DBSCANでは、STEP2までの操作をすべての点にクラスタが割り振られるまで行います。
すべての点に対してクラスタの割り振りやノイズの判断ができれば、DBSCANのアルゴリズムは終了です。
【補足】DBSCANで設定する2つのパラメータ
DBSCANを行う際にパラメータを設定しなければなりません。
設定しなければならないのは以下の2つです。
- ε(イプシロン):距離のしきい値
- 最小のデータ点の数のしきい値
ε(イプシロン)は距離のしきい値で、選択した点からどこまでを範囲とするかを決定します。
また、範囲内に何個のデータ点があれば、クラスタとするのかも設定しなければなりません。
これら2つのパラメータの設定によって結果が大きく異なるため、DBSCANを行う場合は注意しましょう。
データサイエンスを総復習するなら「スタアカ」がおすすめ!
\【破格】たった月980円で学べる!/
いつでも解約できます!
DBSCANでクラスタリングを行うメリット
DBSCANでクラスタリングを行うメリットは以下の3つです。
- クラスタ数を設定しなくてよい
- 外れ値の影響を受けにくい
- どのようなデータの分布もクラスタリングできる
他のクラスタリング手法のデメリットをなくした手法がDBSCANです。
それぞれ解説していきます。
クラスタ数を設定しなくてよい
DBSCANはクラスタ数を事前に設定する必要がないため、最適なクラスタリングが行えます。
k-means法では、クラスタリングの精度がクラスタ数によって変化してしまいます。
しかし、DBSCANではクラスタ数を設定しなくても、アルゴリズムで自動で最適なクラスタ数に分けられます。
そのため、事前にクラスタ数を決めないクラスタリングでは、DBSCANも検討しましょう。
外れ値の影響を受けにくい
DBSCANは点間の密度によってクラスタリングを行うため、外れ値の影響を受けにくい特徴があります。
距離内にある点のみをクラスタとするDBSCANのアルゴリズムでは、外れ値はノイズ点として処理されるのです。
外れ値があるデータの場合は、DBSCANでクラスタリングを行いましょう。
どのようなデータの分布もクラスタリングできる
DBSCANでのクラスタリングはデータの分布に左右されません。
点同士の距離を判断基準とするため、データの分布より密度が優先されるのです。
他のクラスタリング手法に比べて、万能である点がメリットになります。
DBSCANでクラスタリングを行うデメリット
DBSCANにはメリットだけでなく、デメリットも存在します。
しっかりとデメリットも把握したうえで、DBSCANを行いましょう。
DBSCANを行う場合のデメリットは以下の3点です。
- 計算コストが高い
- 密度が異なるデータに適用できない
- パラメータの設定が難しい
以下でそれぞれ解説していきます。
計算コストが高い
DBSCANは各点ごとでクラスタを割り振るため、大規模なデータに対しては計算コストが高くなる傾向にあります。
とはいえ、クラスタリング自体が計算コストが高い傾向にあるため、仕方がないことでもあります。
k-means法と比べて、DBSCANの方が計算が早い場合もあるため、使い分けることをおすすめします。
密度が異なるデータに適用できない
DBSCANは密度でクラスタリングを行うため、密度がデータ間で異なる場合に精度が悪くなります。
例えば、下図のような場合が密度が異なる場合にあたります。
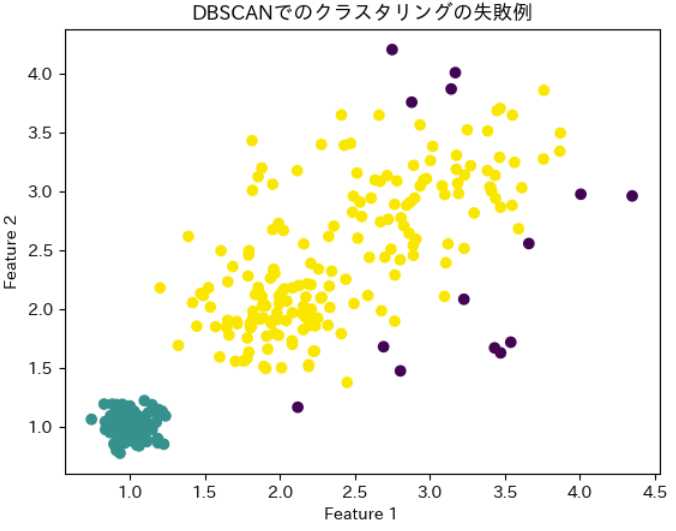
上図のデータは、それぞれのクラスタで密度が異なっていますよね。
このような場合には、距離ε(イプシロン)を設定するのが難しく、精度が悪くなるのです。
そのため、密度が異なる場合は他のクラスタリング手法を検討する必要があります。
パラメータの設定が難しい
DBSCANでは2つのパラメータを設定する必要があるため、パラメータの設定に精度が左右されてしまいます。
以下の例が距離のしきい値を変化させたことによる結果の違いです。

上図の記載の通り、距離のしきい値を0.3から0.5に変化させた結果、精度が著しく悪くなってしまいました。
このように、どのようにパラメータを設定するかで結果が大きく変わるのがDBSCANの特徴です。
必ずクラスタリング結果をグラフ化し、パラメータを変化させながら最適なパラメータを設定するようにしましょう。
DBSCANはPythonで簡単に行える
PythonでDBSCANを実行するためには、scikit-learnライブラリを使用します。
以下がDBSCANの部分だけを抜き出したコードです。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)DBSCANの()の内で2つのパラメータを設定し、DBSCANを行っています。
パラメータの対応関係はそれぞれ以下の通りです。
- eps:距離のしきい値であるε(イプシロン)の先頭3文字
- min_samples:最小のデータ点の数のしきい値
今回の例では、距離のしきい値を0.3、最小のデータ点の数が5個と設定しています。
以下では、今回の解説で紹介したサンプルデータでDBSCANによるクラスタリングを行います。
以下が、サンプルデータの作成からクラスタリング後のグラフ化までを行うPythonコードです。
# ライブラリのインポート
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
# 月型のサンプルデータの作成
X, y = make_moons(n_samples=200, noise=0.05, random_state=1)
# DBSCANによるクラスタリングの実施
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)
# クラスタリング結果を散布図で表示
labels = dbscan.labels_
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()上記のコードを実行すると以下のようなクラスタリング結果になります。
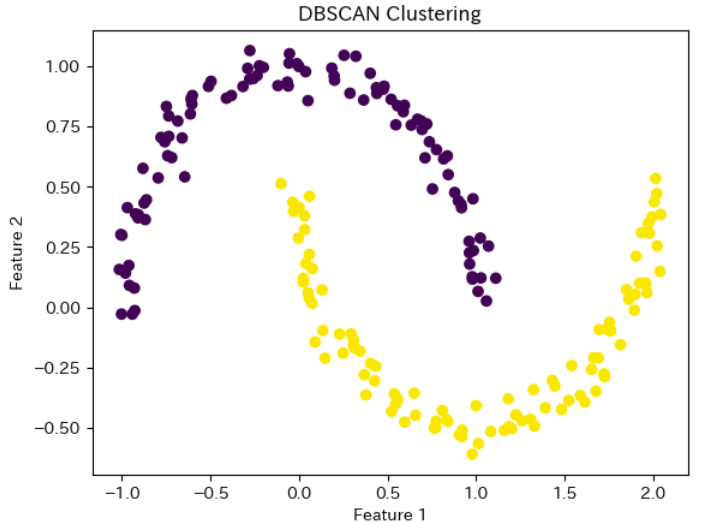
ぜひ、上記のPythonコードを活用して、特殊なデータのクラスタリングを行ってみてください。
まとめ
DBSCANはデータの密度で判断してクラスタリングを行う手法です。
密度からクラスタリングを行うため、特殊なデータ分布のデータのクラスタリングを行えることがメリットです。
DBSCANのアルゴリズムは以下の3ステップで成り立っています。
- 適当な点を選択し、その点と一定距離にある点の数を数える
- 点の数がしきい値以上ならクラスタにし、未満ならノイズ点とする
- これまでの操作を点を変えて繰り返す
適当な点を選択し、事前に決定したしきい値を基にクラスタを割り振ります。
DBSCANを行う際に設定しなければならないパラメータは以下の2つです。
- ε(イプシロン):距離のしきい値
- 最小のデータ点の数のしきい値
PythonでDBSCANを行う場合にも上記のパラメータを設定する必要があるため、覚えておきましょう。
パラメータの値を変化させながら、クラスタリング結果をグラフ化し、最適なクラスタリングを行うようにしましょう。
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}