


- グリッドサーチってなに?
- 最適なハイパーパラメータって?
- 交差検証とは何が違うの?
- Pythonでどうやって実装するの?
とお悩みではありませんか?
本記事では、グリッドサーチのやり方やPythonでの実装、交差検証との関係性について解説していきます。
グリッドサーチとは、ハイパーパラメータを調整するための手法です。
ハイパーパラメータの設定によって、モデルの精度が大きく変わるため、実務では必ずと言っていいほど用いられます。
本記事の信頼性
以下でお悩みの方に読んで欲しい
- グリッドサーチってなに?
- そもそもハイパーパラメータとは?
- どうやってやるの?
- グリッドサーチをPythonで行いたい
- 交差検証と組み合わせるとは?
- 注意点はあるの?

それでは本編です!
月額980円で学べる!
「データサイエンスの復習に手が回らない...」と悩んでいませんか。
僕も学びながら常々感じていました...
データサイエンスは範囲が膨大すぎて、参考書だけでも山ほど...
いちいち見返すのに苦労しますよね。
でも、そんな悩みを解決してくれるサービスを見つけました!
たった月額980円でサクッと学べる『スタアカ』

動画形式でながら聴きもOK、サクッとデータサイエンスを復習できます。
『何冊も参考書を読み直して行き来する苦労』はもう必要ありません。
サブスクなのでいつでも解約可能。今から始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも...
グリッドサーチとは
グリッドサーチとは、モデルのハイパーパラメータをチューニングにするために用いられる手法です。
ハイパーパラメータは、モデルで設定する定数のことで、モデルの精度に大きく影響するパラメータになります。
このハイパーパラメータを適切に設定しなければモデルの精度が悪くなります。
グリッドサーチを用いることで、全通りのハイパーパラメータの組み合わせを検証し、最適なパラメータを見つけ出せるのです。
ハイパーパラメータについて解説します
【補足】そもそもハイパーパラメータとは
ハイパーパラメータとは、モデルを作成する際に設定するパラメータです。
ハイパーパラメータを適切に設定しなければ、モデルの学習が上手く行かず、精度に影響を及ぼします。
例えば、以下のようなパラメータがハイパーパラメータです。
- k近傍法の近傍点(k)の数や距離尺度
- SVMのカーネル関数やカーネルの幅
k近傍法のパラメータについて詳しく知りたい方は『k近傍法(kNN)とは?仕組みからpythonでの実装までわかりやすく解説!』の記事をご参照ください。

以下からグリッドサーチのやり方について解説していきます
グリッドサーチのやり方3ステップ
グリッドサーチは、次の3ステップで行われます。
- それぞれのハイパーパラメータの候補値を設定する
- ハイパーパラメータの組み合わせを変えてモデルを学習する
- モデルの評価を行う
Pythonでグリッドサーチを行う際にも上記の流れでコードを記載するため、しっかりと流れを把握しておきましょう。
今回のステップの説明のために、実際にSVM(サポートベクターマシン)でハイパーパラメータを調整します。
それぞれ解説していきます
STEP1.それぞれのハイパーパラメータの候補値を設定する
まず、設定しなければならないハイパーパラメータを探し、その値の候補を設定します。
ハイパーパラメータを探すうえで、そのモデルについて詳しく理解しておかなければなりません。
SVMで設定すべきハイパーパラメータは以下の2つです。
- カーネル関数の種類
- 正則化のパラメータ
カーネル関数内のパラメータを設定することがありますが、今回は2つを調整していきます。
2つのハイパーパラメータはそれぞれ以下の候補が挙げられます。
- カーネル関数の種類:線形(linear)・非線形(rbf)
- 正則化のパラメータ:0.1・1・10
これらの候補を挙げることができれば、次にモデルの学習に移ります。
STEP2. ハイパーパラメータの組み合わせを変えてモデルを学習する
指定したハイパーパラメータの組み合わせごとに、モデルを学習していきます。
全組み合わせで学習を行うことにより、異なるハイパーパラメータ設定でモデルを評価できるのです。
どのデータで繰り返しモデルの学習するの?
モデルの学習は、訓練データを更に以下の2つに分割して行います。
- 訓練データ
- 検証データ
テストデータは適切なハイパーパラメータが決定してから、テストのために用います。
そのため、グリッドサーチには訓練データを更に分割して擬似的にテストデータを作るのです。
図に表すと以下のようになります。
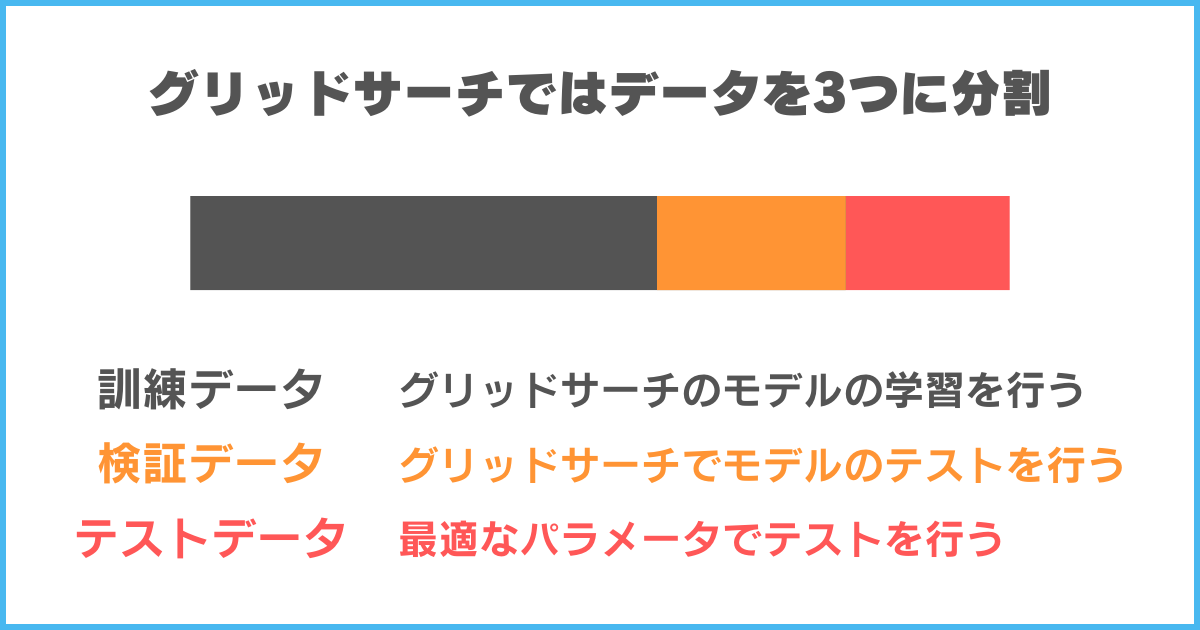
元のデータを上図のように分割し、検証データをグリッドサーチのテストデータをするのです。
また、この検証データに分割する時に、交差検証を用いることでモデルの精度を上げていきます。
交差検証について詳しく知りたい方は『交差検証法とは?種類やPythonの実装・ホールドアウト法との違いまでわかりやすく解説』の記事をご参照ください。

交差検証法との組み合わせに関しては、Pythonでの実装の【補足】にて詳しく解説しております。
では、最後にモデルの評価を行っていきましょう。
STEP3. モデルの評価を行う
各ハイパーパラメータの組み合わせで学習したモデルを評価指標を用いて評価します。
評価指標について詳しく知りたい方は『機械学習の評価指標はどう選ぶ?回帰、分類の評価指標をわかりやすく解説』の記事をご参照ください。

機械学習手法によって、使用する評価指標を変えるようにしましょう。
今回は分類手法であるSVMを例としているため、以下のような指標からモデルの精度を評価します。
- 正解率
- 適合率
- 再現率
- F値
各ハイパーパラメータの組み合わせを上記の評価指標で評価し、最も精度が良かったハイパーパラメータを採用します。
そして、採用したハイパーパラメータを設定したモデルでもう一度学習(訓練データ+検証データ)を行い、テストデータで評価をするのです。
このように、各ハイパーパラメータでモデルを学習し検証データで評価を行うのが、グリッドサーチの特徴になります。
グリッドサーチはPythonで簡単に行える
グリッドサーチはPythonを用いて簡単に実行できます。
今回紹介するコードは、グリッドサーチに交差検証法を用いています。
なぜ交差検証法と組み合わせているのかを知りたい方は補足をご参照ください。
それでは、以下がサンプルデータの作成からグリッドサーチの実行、最終的なモデルの評価までを行うコードになります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import make_blobs
# サンプルデータを生成
X, y = make_blobs(n_samples=100, centers=2, random_state=6)
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#ハイパーパラメータの設定
param_grid = {
'kernel': ['linear', 'rbf'],
'C': [0.1, 1, 10]
}
# グリッドサーチの実行、cv=5は5分割交差検証
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 最適なハイパーパラメータを変数に格納
best_kernel = grid_search.best_params_['kernel']
best_C = grid_search.best_params_['C']
# 最適なハイパーパラメータでモデルを学習
svm_model = SVC(kernel=best_kernel, C=best_C)
svm_model.fit(X_train, y_train)
# テストデータで予測
y_pred = svm_model.predict(X_test)
# モデルの性能を評価
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
# 結果の出力
print(f"最適なカーネル: {best_kernel}")
print(f"最適なC: {best_C}")
print(f"テストデータの正解率: {accuracy}")
print("分類レポート:\n", classification_rep)param_gridの部分がハイパーパラメータの候補を変数に格納している所です。
そして、GridSearchCV()で、グリッドサーチと交差検証法を組み合わせて実行しています。
classification_report(y_test, y_pred)とは、下図のような評価レポートの出力を行ってくれる関数です。
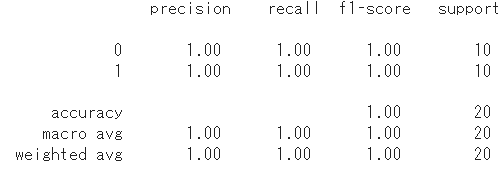
左から適合率・再現率・F値と算出してくれる関数になります。
このように、グリッドサーチを用いることで、最適なハイパーパラメータでモデルを学習できるのです。
ちなみに、分類結果を散布図に出力すると下図のようになります。
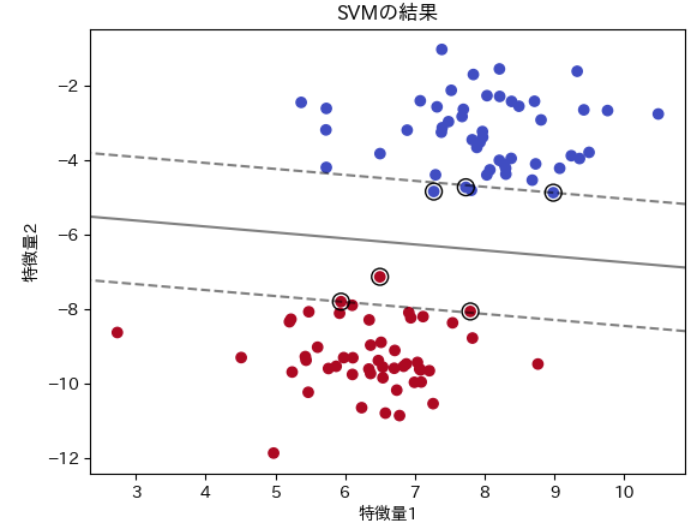
綺麗に分類されていて、モデルの精度が高いことが見て取れますね。
散布図の算出のコードも併せて下記に記載しておきます。
!pip install japanize-matplotlib
import japanize_matplotlib
# データポイントの散布図をプロットします。
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm')
# 決定境界を描画します。
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# メッシュグリッドを生成します。
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50), np.linspace(ylim[0], ylim[1], 50))
xy = np.c_[xx.ravel(), yy.ravel()]
# メッシュグリッド上のデータに対する予測を行います。
Z = svm_model.decision_function(xy).reshape(xx.shape)
# 決定境界をプロットします。
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
# サポートベクトルをプロットします。
ax.scatter(svm_model.support_vectors_[:, 0], svm_model.support_vectors_[:, 1], s=100,
linewidth=1, facecolors='none', edgecolors='k')
plt.xlabel('特徴量1')
plt.ylabel('特徴量2')
plt.title('SVMの結果')
plt.show()先頭2行でグラフの出力に日本語が対応できるようなモジュールをインポートしています。
日本語を用いる場合は必ず先頭2行も含めるようにしてください。
交差検証とグリッドサーチを組み合わせる理由について解説します
【補足】交差検証とグリッドサーチを組み合わせるとは
一般に、グリッドサーチは交差検証と組み合わせて用いられます。
交差検証法とは、データを何等分かに分け、訓練データとテストデータの割り振りを変えながらモデルの学習、評価を繰り返す手法です。
グリッドサーチには、1つのハイパーパラメータの組み合わせに対して、交差検証法が1回用いられます。
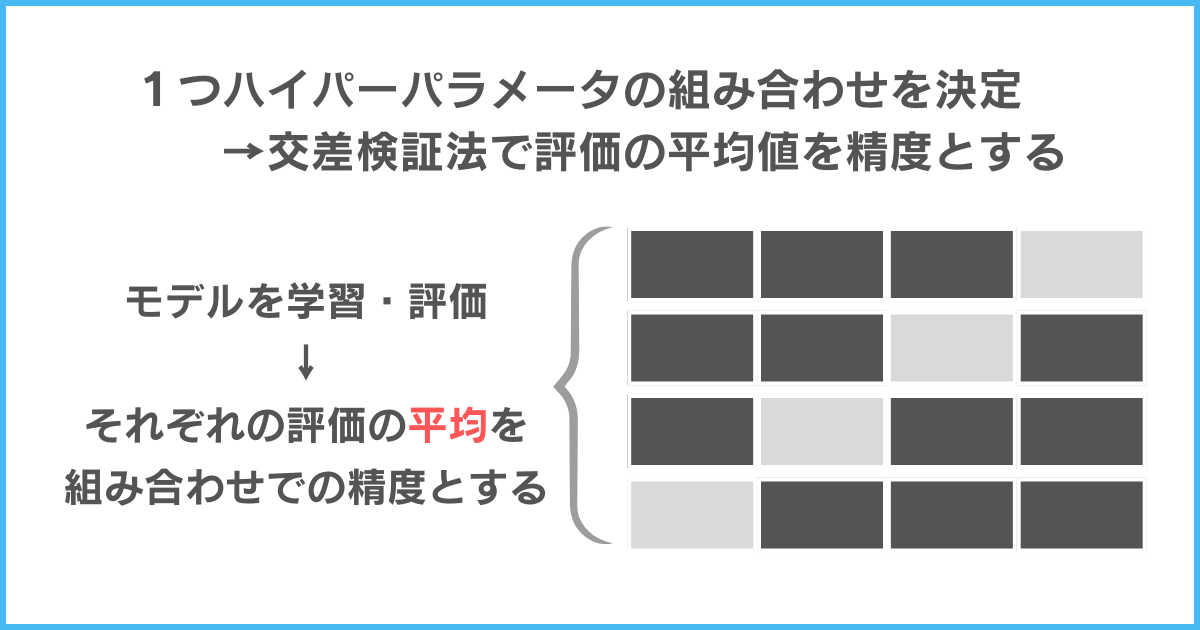
上図のように1回のハイパーパラメータの組み合わせを調べるのに交差検証を用いるのです。
交差検証を用いることで、評価の平均値を取れ、偶然による評価のブレを抑えられます。
このように、交差検証を用いることで偶然の影響を取り除き、最適なハイパーパラメータを選択できるようにするのです。
グリッドサーチを行う際の3つの注意点
グリッドサーチを行う際、以下の3つの点に注意しましょう。
- ハイパーパラメータの中身を理解しておく
- ベースとなるハイパーパラメータを把握しておく
- ハイパーパラメータに重要度をつける
ネット検索すると多くのPythonコードがありますが、そのまま使ってはいけません。
上記の注意点を確認してからグリッドサーチを行うようにすることをおすすめします。
それぞれ解説していきます。
ハイパーパラメータの中身を理解しておく
グリッドサーチを行う前に、ハイパーパラメータの中身(意味や影響)を理解しておきましょう。
1つ1つのハイパーパラメータがモデルの学習にどれだけ影響するのかを把握していなければ、最適なハイパーパラメータがなんでそう決まったのかを解釈できません。
そのため、それぞれのハイパーパラメータがどのような役割かを把握して、モデルの学習を行うことをおすすめします。
ベースとなるハイパーパラメータを把握しておく
グリッドサーチを行う前に、基準となるハイパーパラメータを把握しておくことが大切です。
もし基準となるハイパーパラメータの値を把握していなければ、見当違いのハイパーパラメータの候補を設定してしまいかねません。
基準となるハイパーパラメータを知った上で、その周辺の値を候補として設定することで、より効率的なグリッドサーチを行えるのです。
ハイパーパラメータに重要度をつける
ハイパーパラメータによっても重要度をつける必要があります。
もし、すべてのハイパーパラメータを同じ重要度であると考えてしまうと、どのハイパーパラメータを調整したらいいか迷ってしまいます。
そのため、事前に重要度をつけることで、ハイパーパラメータの調整の順番の参考にするのです。
このように、グリッドサーチではハイパーパラメータについて事前に準備することが多くあります。
慣れるまでは、毎回確認してからモデルを作成するようにしましょう。
まとめ
グリッドサーチは、モデルの学習の時にハイパーパラメータを最適なものにするための手法です。
ハイパーパラメータチューニングの手法と呼ばれ、ハイパーパラメータによってモデルの精度が大きく変わります。
グリッドサーチは以下の3ステップで行います。
- それぞれのハイパーパラメータの候補値を設定する
- ハイパーパラメータの組み合わせを変えてモデルを学習する
- モデルの評価を行う
Pythonで実装する際にも上記のステップで行います。
グリッドサーチをPythonで行う時に交差検証と組み合わせて、モデルの精度を向上させます。
また、グリッドサーチは3つの注意点に気を付けましょう。
- ハイパーパラメータの中身を理解しておく
- ベースとなるハイパーパラメータを把握しておく
- ハイパーパラメータに重要度をつける
ハイパーパラメータについてしっかり理解したうえで、グリッドサーチを行う必要があります。
これらの点を押さえて、正しくグリッドサーチでハイパーパラメータを設定しましょう。
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}