


「交差エントロピーってなに?」
「何に使われるの?」
「どうやって計算するの?」
とお悩みではありませんか。

勉強していると何に利用できるのか忘れてしまいがちですよね...
交差エントロピーとは、機械学習の分類モデルの誤差を計算する損失関数です。
モデルの誤差を計算するために交差エントロピーが必要なので、機械学習では必ず押さえるべきポイントになります。
そこで、本記事では交差エントロピーの概要から計算方法、Pythonでの実装まで解説していきます。
最後まで読めば、交差エントロピーを活用して分類モデルを作れるようになれます!
本記事の信頼性
以下でお悩みの方に読んで欲しい
月額980円で学べる!
データサイエンスの復習は完ぺきにできていますか?
データサイエンスは勉強する範囲が膨大で、復習に手が回りませんよね。
そんなあなたにおすすめなのが、たった月額980円でサクッと学べる『スタアカ』

数分の動画でビジネスへの活用法も含めて、サクッとデータサイエンスを復習可能。
『何冊も参考書を往復して復習する苦労』とはおさらばです!
サブスクなのでいつでも解約OK。手軽に始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも!
それでは本編です!
交差エントロピーとは

交差エントロピーとは、機械学習で分類を行うモデルを作成した後に、予測値と実際の値との誤差を見るための関数です。
交差エントロピーを用いることで、それぞれの分類の予測結果と実際の値の誤差を数値化できます。
交差エントロピーの一般的な式は以下の通りです。
\[ H(y, \hat{y}) = -\sum_{i} y_i \log_2(\hat{y_i}) \]
以上の式では、それぞれ、
- \( y \):実際の分類結果
- \( \hat{y} \):予測の分類結果
の値が入り、分類による誤差を数値で求めます。
また、Σの中の\( y_i \)と\( \hat{y_i} \)はそれぞれ、
- \( y_i \):実際の分類結果1回分
- \( \hat{y_i} \):予測の分類結果1回分
であることも押さえておきましょう。
それぞれの分類の誤差を計算して、足し合わせるイメージを持っておくとよいです。
そのため、機械学習を用いた分析を行いたい方は必ず交差エントロピーでの誤差の計算方法を押さえておきましょう。
二乗和誤差とはどう違う?
二乗和誤差と交差エントロピー誤差は、どちらも機械学習の損失関数として用いられますが、利用用途が異なります。
それぞれの利用用途は以下のように区別して理解しておきましょう。
- 回帰:二乗和誤差
- 分類:交差エントロピー
二乗和誤差は実際の値と予測値の差の二乗を計算しますが、交差エントロピーは実際の値と予測値の違いを数値化します。
2つの関数はどちらも、それぞれの点・項目について誤差を計算して足し合わせている同じ考え方の関数です。
そのため、区別は必要ですが、両方は同じような考え方で解いていると意識するとよいでしょう。
交差エントロピーの計算方法【例題つき】

交差エントロピーの計算方法について説明します。
基本的な計算式は以下の通りです。
\[ H(y, \hat{y}) = -\sum_{i} y_i \log_2(\hat{y_i}) \]
実際に計算する場合、まず実際の値と予測値をそれぞれデータとして持っておく必要があります。
先ほども取り上げたように、実際の値と予測はそれぞれ
- \( y \):実際の分類結果
- \( \hat{y} \):予測の分類結果
の対応関係にあることを押さえておきましょう。
直感的に理解できるように例題で確認していきます。
例題
ある人の特徴からその人の職業を当てる予測を行います。
仕事の選択肢は以下の3択です。
- 弁護士
- 営業マン
- データサイエンティスト
その人はデータサイエンティストでしたが、作成したモデルは以下のように1回の予測を立てました。
- 弁護士である確率:0.1
- 営業マンである確率:0.2
- データサイエンティストである確率:0.7
この時のモデルの誤差を計算しなさい。
3択の分類問題であるため、まず交差エントロピーを用いると良いと分かりますね。
今回は、1回分の分類の誤差を計算するため、Σの中を計算する方法をお伝えします。
計算式に当てはめるための変数はそれぞれ以下の通りです。
- 実際の値(\( y_i \)):
[0, 0, 1] - 予測の値(\( \hat{y_i} \)):
[0.1, 0.2, 0.7]
Pythonのリストのように、[項目1, 項目2, 項目3]と値をそれぞれ当てはめていると考えましょう。
計算式に当てはめると以下のようになります。
数式はスクロールできます
\begin{split}
H(y_i, \hat{y_i}) &= - y_i \log_2(\hat{y_i}) \\
&= -0\log_2(0.1)-0\log_2(0.2)-1\log_2(0.7)
\end{split}
以上の式から分かるように、交差エントロピーの1回分の計算ではそれぞれの項目について誤差を計算して足し合わせます。
回帰の時に行う誤差の計算でも、それぞれの点の誤差を計算するのと同じイメージを持ちましょう。
なんで先頭に\( - \)がつくの?
\( - \)がつくのは、予測値が0から1までの値しか取らず、\( log \)が必ずマイナスの値を取るからです。
なぜ予測値が0から1だと\( log \)がマイナスなのか
\( log \)がマイナスになるのは以下のグラフを見てもらえると理解できます。
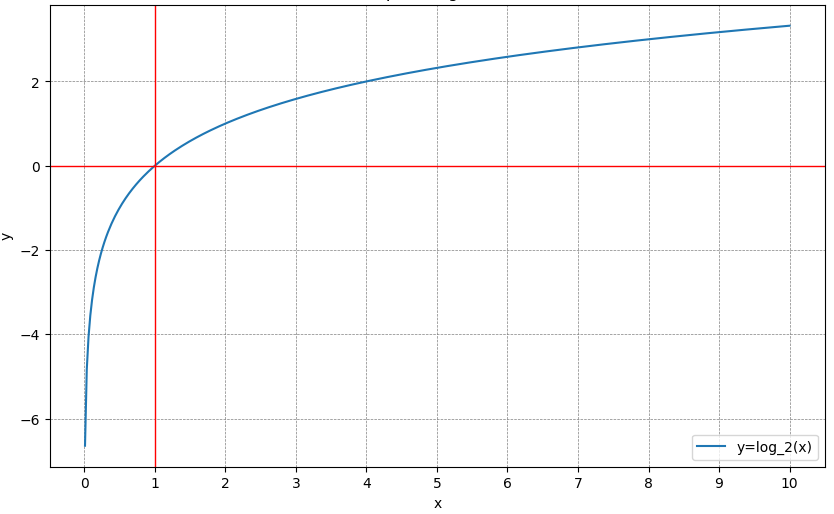
上図のように、\( x \)の値が1になるまでは、logはマイナスの値を取るのです。
例えば、\( log_2(0.5) \)だと、
\[ log_2(0.5) = \log_2(1) - \log_2(2) = -1 \]
とマイナスの値を取ります。
実際に計算式をもとに、計算を進めると以下のようになります。
数式はスクロールできます
\begin{split}
H(y_i, \hat{y_i}) &= - y_i \log_2(\hat{y_i}) \\
&= -0\log_2(0.1)-0\log_2(0.2)-1\log_2(0.7) \\
&= -1\log_2(0.7) \\
&= 0.52
\end{split}
計算を行うと、誤差が0.52であると求められました。
このように、3つ以上の多クラスの分類では、それぞれの項目について誤差を計算します。
2クラスの分類の場合は、少し簡略化できるため、以下で解説していきます。
2クラス分類の場合の交差エントロピーの計算式
2クラス分類は、一般の交差エントロピーの式でも解けますが、もっと計算式を簡略化できます。
なぜなら、予測値の計算がpか1-pに必ずなるためです。
まずは、別の例題を多クラスの分類の交差エントロピーと同じ式で解いてみましょう。
例題
ある受験生が大学に合格するかどうかを判断します。
結果は合格でしたが、作成したモデルは以下のように予測を立てました。
- 合格する確率:0.7
- 合格しない確率:0.3
この時のモデルの誤差を計算しなさい。
この例題では、実際の値と予測値はそれぞれ以下のように整理できます。
- 実際の値(\( y \)):
[1, 0] - 予測の値(\( \hat{y} \)):
[0.7, 0.3]
以上の式の\( y \)と\( \hat{y} \)は、先ほどまでの\( y \)と\( \hat{y} \)とは違うので、注意してください。
交差エントロピーの式に当てはめてみると、以下のような計算です。
\begin{split}
H(y_i, \hat{y_i}) &= - y_i \log_2(\hat{y_i}) \\
&= -1\log_2(0.7)-0\log_2(0.3) \\
&= -1\log_2(0.7) \\
&= 0.52
\end{split}
このように普通の方法でも計算を行えますが、もっと簡単な公式が以下の通りです。
数式はスクロールできます
\[ H(y, \hat{y}) = -y\log_2(\hat{y})-(1-y)\log(1 - \hat{y}) \]
以上の式の\( y \)と\( \hat{y} \)は、先ほどまでの\( y \)と\( \hat{y} \)とは違うので、注意してください。
例題をもっと簡単に読み解くと、
- 実際の値(\( y \)):合格する確率は1
- 予測の値(\( \hat{y} \)):合格する確率は0.7
と考えられ、合格しない確率は合格する確率pから引き算をする1-pで求められます。
そのため、初めから展開した状態で計算できるのです。
ロジスティック回帰分析などの2値の分類問題では、簡単な公式の方が利用されるので注意しておきましょう。
データサイエンスを総復習するなら「スタアカ」がおすすめ!
\【破格】たった月980円で学べる!/
いつでも解約できます!
Pythonで交差エントロピーを計算する方法
Pythonで交差エントロピーを計算する方法を解説していきます。
numpyという数式を扱うライブラリを用いて、交差エントロピーの関数を作成しているのが以下のコードです。
多クラスの分類で用いた例題を解くコードが以下になります。
import numpy as np
# 交差エントロピーの計算1回分の公式を関数化
def cross_entropy(p, q):
return -np.sum(p * np.log2(q))
# 実際の値
p = np.array([0, 0, 1])
# 予測値
q = np.array([0.1, 0.2, 0.7])
# 交差エントロピーの計算
result = cross_entropy(p, q)
print("Cross Entropy:", result)作成したcross_entropy関数は、実際の値pと予測値qを引数として受け取って、交差エントロピーを計算して返しています。
このようにして、Pythonで簡単に交差エントロピーを計算することができます。
まとめ
交差エントロピーは機械学習で分類を行うモデルの予測値と実際の値との誤差を見るための関数です。
交差エントロピーを用いることで、それぞれの分類の予測結果と実際の値の誤差を数値化できます。
交差エントロピーの計算式は以下の通りです。
\[ H(y, \hat{y}) = -\sum_{i} y_i \log_2(\hat{y_i}) \]
2クラス分類verの交差エントロピーの計算式も良く用いられるので、あわせて押さえておきましょう。
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}