


・機械学習の評価ってどうやってするの?
・どの評価指標を選んだらいいの?
と悩んではいませんか?
本記事では、機械学習の評価指標について、回帰、分類のそれぞれについて数式も含めて解説していきます。
機械学習の評価指標はそれぞれ4つずつです!
本記事の信頼性
こんな悩みがある方読んで欲しい
- 機械学習の評価ってどうやるの?
- 回帰の評価指標は?
- 分類の評価指標は?
- 評価指標を使う際の注意点はある?

それでは本編です!
月額980円で学べる!
データサイエンスの復習は完ぺきにできていますか?
データサイエンスは勉強する範囲が膨大で、復習に手が回りませんよね。
そんなあなたにおすすめなのが、たった月額980円でサクッと学べる『スタアカ』

数分の動画でビジネスへの活用法も含めて、サクッとデータサイエンスを復習可能。
『何冊も参考書を往復して復習する苦労』とはおさらばです!
サブスクなのでいつでも解約OK。手軽に始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも!
機械学習の評価指標とは
機械学習において評価指標は最も大切です。
アルゴリズムや手法を用いたモデルを構築しても、返ってきた結果が正しいのかを判定しなくてはなりません。
なぜ評価指標が必要なのか、しっかりと整理していきましょう。
機械学習で評価指標を用いる目的
機械学習の評価指標はモデルの性能を評価するために用いられます。
具体的に以下の3つのことに役に立つのが評価指標です。
- モデルの予測性能の客観的評価
- 異なるモデルやパラメータの比較
- モデルの強みや弱みの理解
評価指標を用いることで客観的にモデルを評価できます。
また、モデル同士を比較するのにも評価が必要です。
同じ評価指標を用いることでそれぞれのモデルの強み、弱みを把握できます。
機械学習における評価指標

機械学習は「分類」と「回帰」の2つに分かれており、それぞれ評価指標があります。
回帰タスクなのに分類タスクに用いる評価指標を誤って用いてしまうと正しい評価ができません。
回帰タスクと分類タスクに分けて紹介していきます!
回帰タスクの評価指標
予測タスクには主に4つの評価指標があります。
- 平均絶対誤差 (MAE)
- 平均二乗誤差 (MSE)
- 二乗平均平方根誤差 (RMSE)
- 決定係数 (R2)
決定係数を除いた3つの指標は誤差の指標で、値が小さければ良い指標です。
それぞれについて数式も含めて解説していきます。
1. 平均絶対誤差 (MAE)

平均絶対誤差(MAE)は予測値と実際の値の差の絶対値の平均を表す指標です。
2乗やルートが出てこないためそのままの値でも評価できます。
平均絶対誤差の式は以下の通りです。
$$MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|$$
誤差の絶対値の和をデータの数で割っています。
平均絶対誤差の値が小さいほど精度の高いモデルと言える指標です。
2. 平均二乗誤差 (MSE)

平均二乗誤差(MSE)は予測値と実際の値との差の二乗の平均を表す指標です。
二乗するため絶対値を用いなくてよいという特徴があります。
平均絶対誤差と同様に小さければ小さいほど良い指標です。
平均二乗誤差を求める式は以下になります。
$$MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$$
二乗しているため、本当の誤差より大きくなることに注意してください。
3. 二乗平均平方根誤差 (RMSE)

二乗平均平方根誤差(RMSE)は平均二乗誤差の平方根となる指標です。
平均二乗誤差が二乗の計算であることから、実際の値の単位と揃えるために利用されます。
二乗平均平方根誤差の式は以下の通りです。
$$RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}$$
平均二乗誤差と二乗平均平方根誤差の対応関係を頭に入れておきましょう。
4. 決定係数 (R2)

決定係数は予測値が目的変数の変動をどれだけ説明しているかを示す指標です。
0から1の範囲の値を取り、予測したモデルがどれだけ実際の値にあてはまっているのかを示します。
式は以下の通りです。
$$R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2}$$
1に近づいている方が良いモデルと言えますが、過学習しているかどうかを確認しましょう。
分類タスクの評価指標
分類タスクはすべて混合行列から導ける評価指標です。
混合行列とは実際の値と予測値の2つの結果を示した表になります。
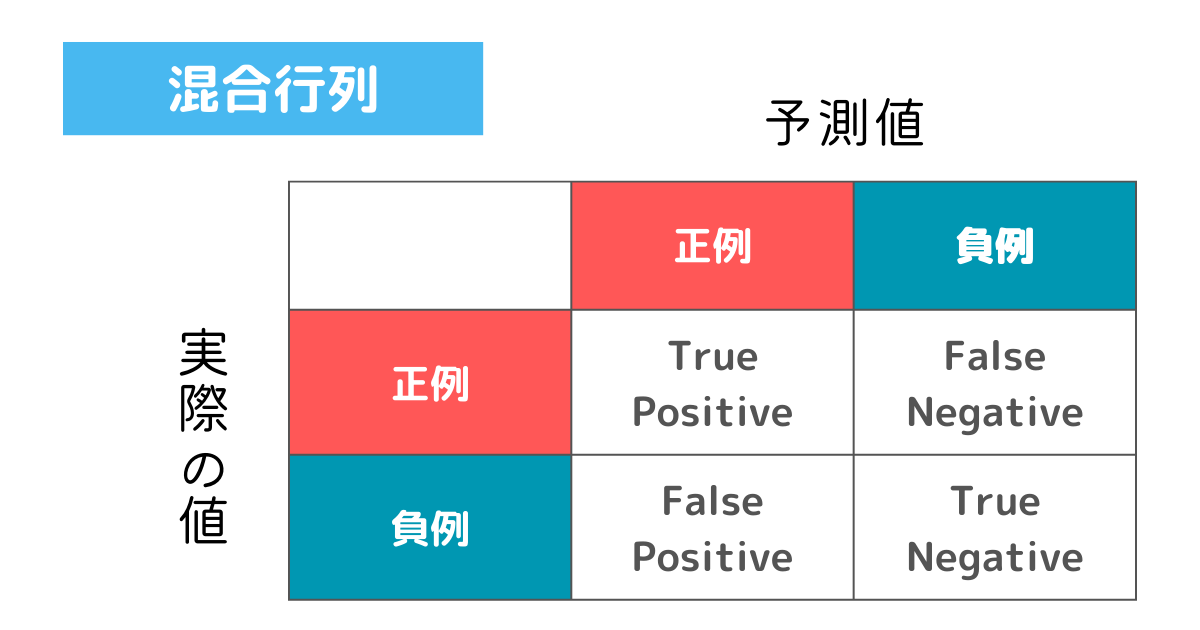
混合行列には正例、負例の2つのカテゴリがあり、それぞれのマスで呼び名が決まっています。
- TP : True Positive
- FN : False Negative
- FP : False Positive
- TN : True Negative
覚えられない......
それぞれのマスの英語は、予測が正しかったかどうかを示してると考えてみましょう。
特に分かりにくいFP,FNについて解説します。
FPは実際値が負例で予測値が正例ですよね。
Positiveは正例と同じ意味なので、この場合FPは正例ではなかった、と訳せます。
FPは予測値が正例ではなかった、と覚えるようにしましょう!
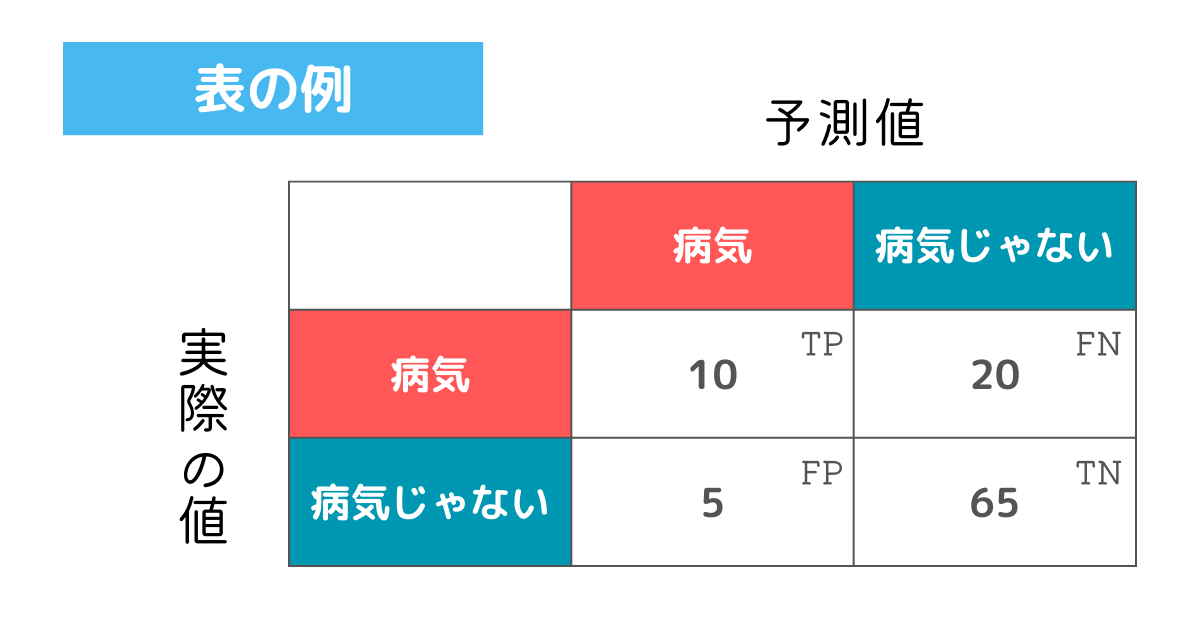
今回はイメージしやすいように病気かそうじゃないかを例に評価指標を紹介していきます。
それでは解説していきます!
1. 正解率 (Accuracy)
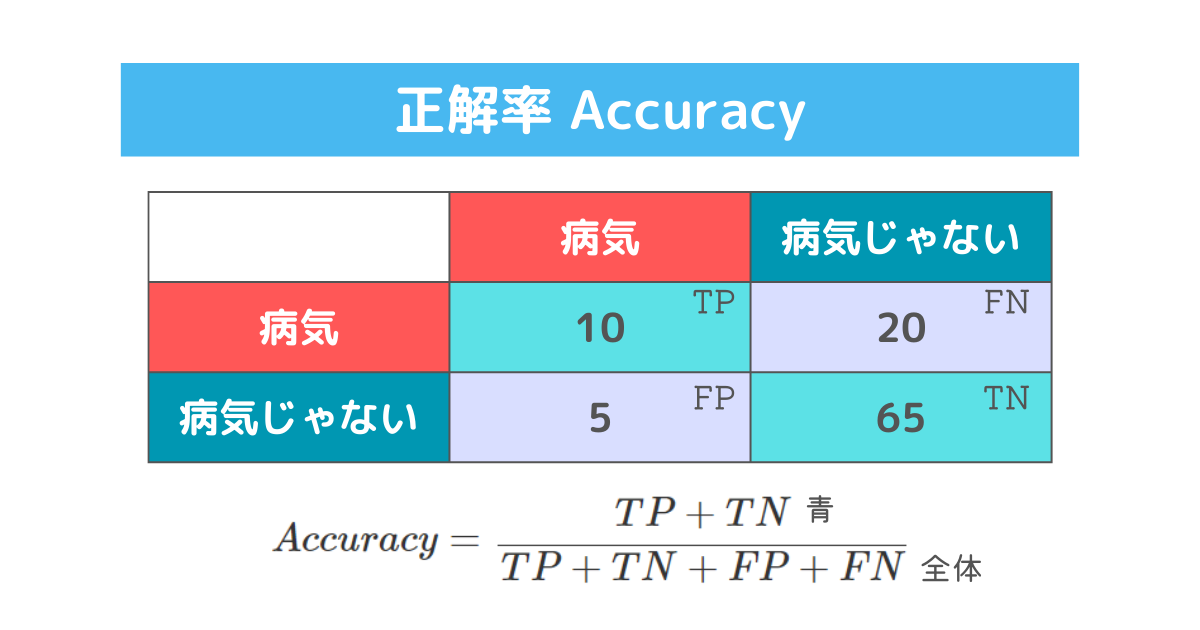
正解率はどれだけ正しく分類できたかの割合を示す指標です。
直感的にどれだけ正しいのかを理解できる点で良く用いられます。
正解率の公式から例の表を用いて解いてみましょう。
$$Accuracy = \frac{TP + TN}{TP + TN + FP + FN} = \frac{10 + 65}{10 + 65 + 5 + 20} = \frac{3}{4}$$
Trueとついているマスを正しいとして計算します。
例から計算すると正解率が75%であるので、ある程度正しいと結論づけられます。
全世界で0.01%しかならない病気などの場合、病気じゃない例がほとんどになり、そこまで正しいとは言えないのに値が大きくなるので注意です。
2. 適合率 (Precision)

適合率は予測で正例と判断した中でどれだけが実際に正例であるかの割合の指標です。
適合率を見ることで本当は病気じゃないのに病気と判断されてしまうことを検知できます。
適合率の公式から例の問題を解いてみましょう。
$$Precision = \frac{TP}{TP + FP} = \frac{10}{10 + 5} = \frac{2}{3}$$
適合率は約67%であると算出されました。
裏を返せば、33%の人は病気じゃないのに病気と判断されてしまっている(偽陽性)とも捉えられます。
3. 再現率 (Recall)

適合率は実際に正例であるものの中でどれだけ正しく予測できているかの割合の指標です。
適合率を見ることで本当は病気なのに病気じゃないと判断されてしまうことを検知できます。
再現率も例の問題でイメージしてみましょう。
$$Recall = \frac{TP}{TP + FN} = \frac{10}{10 + 20} = \frac{1}{3}$$
適合率と違い33%と低い値が出てしまいました。
今回は適当に値を定めましたが、再現率が33%は良くないモデルです。
次で解説するF値で適合率と再現率をどちらも考慮した値を見ていきましょう。
4. F値 (F1-score)

F値は適合率と再現率の調和平均を表す指標です。
F値を用いることで、適合率と再現率の両方の値をバランスよく評価することができます。
まずは値を確認してみましょう。
$$F1 = \frac{2 \cdot Precision \cdot Recall}{Precision + Recall} = \frac{2 \cdot \frac{2}{3} \cdot \frac{1}{3}}{\frac{2}{3} + \frac{1}{3}} = \frac{4}{9} = 0.44\cdots$$
F値は適合率と再現率の調和平均であり、0から1の範囲の値で、1の方が良いとされています。
今回の例は44%であるため、良いモデルとは言えないでしょう。
F値はどちらか一方の値が低くなれば値が0に近づく特徴があり、今回は再現率が低くなっていたのが原因です。
このようにF値までを算出することで予測モデルがどれだけ良いかを全体として考察できます。
『k近傍法』の記事で評価指標を用いてモデルを評価しています。ご参照ください!
-

k近傍法(kNN)とは?仕組みからPythonでの実装までわかりやすく解説!
続きを見る
機械学習の評価をする時の3つの注意点
機械学習の評価を行う際には、以下の3つの注意点を抑えておきましょう。
- 適切な評価指標を選ばなければならない
- 評価指標から結果の解釈を行わなければならない
- 評価が正しくてもモデルの性能が高いとは言いきれない
評価指標は評価を行うための客観的な数値であるだけで、評価を行うのは人間です。
これらの注意点を意識して、モデルを評価を行いましょう。
それぞれ解説していきます。
適切な評価指標を選ばなければならない
機械学習の評価を行う際には、適切な評価指標を選ばなくてはなりません。
求めたいデータによって必要な評価指標は異なります。
例えば、病気の人をどれだけ漏れなく見つけられているのかを知りたいのであれば、再現率を算出するといった形です。
どのような用途でモデルを使用するのか、から評価指標を選択するようにしましょう。
評価指標から結果の解釈を行わなければならない
評価指標から結果の解釈を必ず行ってください。
評価指標の値を算出しても単なる数値でしかなく、そのままでは使い物になりません。
結果の解釈を行うことで、どのような特性のモデルであるのかを説明できるようにしましょう。
評価が正しくてもモデルの性能が高いとは言いきれない
たとえ評価指標の値がすべて良くても、モデルの性能が高いと言いきれないのが注意点です。
評価指標は与えられたデータから算出した数値であるため、モデル自体に欠陥があっても良い値を返すことがあります。
例えば、モデルが過学習している時、評価指標は高くなりますが、未知のデータには対応できなくなるでしょう。
まとめ
機械学習において評価指標はモデルの性能を評価するために重要です。
回帰タスクと分類タスクでそれぞれ評価指標が異なるため、回帰や分類を行う際の評価には注意してください。
数値を算出するだけでなく、正しく結果を解釈することも忘れてはいけません。
評価指標をうのみにしすぎず、モデルの評価を行うようにしましょう!
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}