


- 過学習ってなに?
- 過学習ってどう対策するの?
とお悩みではないですか?
本記事では、モデルを作成する上で課題となる過学習について原因や見分け方・対策方法まで解説していきます。
過学習は学習のために用いたデータに過度に適合することで、未知のデータに対する予測精度が低くなってしまう現象です。
本記事の信頼性
気になる所にジャンプできます!

それでは本編です!
月額980円で学べる!
データサイエンスの復習は完ぺきにできていますか?
データサイエンスは勉強する範囲が膨大で、復習に手が回りませんよね。
そんなあなたにおすすめなのが、たった月額980円でサクッと学べる『スタアカ』

数分の動画でビジネスへの活用法も含めて、サクッとデータサイエンスを復習可能。
『何冊も参考書を往復して復習する苦労』とはおさらばです!
サブスクなのでいつでも解約OK。手軽に始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも!
過学習(Overfitting)とは
過学習(Overfitting)とは、データ(訓練データ)に対して過度に適合してしまうことで未知のデータに対する予測性能が低下することです。
過学習が起こってしまうと、作成したモデルはデータのノイズ(極端な値)やそのデータにしかない特徴まで捉えてしまいます。
その結果、他のデータ(分析したい未知のデータ)に対して作成したモデルを用いて予測しても、間違った予測結果を出してしまうのです。
モデルを作成する時に使用したデータを分析する時だけ正しい結果を返せ、他のデータに対しての予測は正しくないことになってしまうのが、過学習の状態となります。
過学習が起こる3つの原因

過学習が起こる原因は主に以下の3つです。
- データが不足している
- データが偏っている
- モデルが複雑になっている
以上の3点のうちどれかにあてはまる時、過学習が起こる可能性が高いです。
これら3つの点に注意したうえでモデルを作成しましょう。
1. データが不足している
データが少ない場合、過学習が起こりやすくなります。
データが少なければ情報量が限られてしまい、作成されたモデルは限られた情報から予測を行わなければならなくなります。
その結果、そのデータに特化したモデルになってしまって過学習が起こります。
できるだけ多くのデータを用いて、色々な情報からモデルを作成できるようにする必要があります。
2. データが偏っている
十分にデータが多くとも、データが偏っていれば、過学習が起こる可能性が高くなります。
特定の要素だけのデータや1パターンのデータだけしか集められていない場合、そのデータで作成したモデルはその特性に適合するため、他の要素の情報を無視してしまいます。
例えば、20代から60代の方が対象の商品である時、集められた情報が55歳の人だけの情報だけしかなければ、作成されたモデルは55歳の人の要素に適合してしまいます。
その結果、他の年代層の人が入っているデータを用いると、予測結果が正しくないということになってしまうのです。
そのため、できるだけ幅広い多様な情報を収集する必要があります。
3. モデルが複雑になっている
作成したモデルが複雑である場合、過学習が起こりやすくなってしまいます。
モデルが複雑であるとは、予測をするために用いる変数の数が多い状態です。
予測のために用いる変数が多いと、少し特別な値(ノイズ)にまで適合しようとしてしまいます。
そのため、少し他のデータになると、特別な値(ノイズ)にまで適合したモデルでは正しい予測ができなくなってしまうのです。
予測精度を上げる時には、モデルが複雑になりすぎないか確認しましょう。
過学習を見分ける3つの方法

過学習の原因について解説しました。
次はどうやって過学習を判断するのかについて解説していきます。
過学習を見分ける方法は以下の3つです。
- ホールドアウト法を行う
- 交差検証法を行う
- 学習曲線を見て判断する
過学習かどうかを客観的に判断できるのが以上の3つの方法です。
それぞれ解説していきます。
1. ホールドアウト法を行う

ホールドアウト法(Holdout-Method)とは、用意したデータを訓練データとテストデータに分け、訓練データでモデルを学習、テストデータでモデルの性能を評価することで過学習していないかを判断する方法です。
用意したデータの大半を訓練データにしてモデルを作成し、テストデータを仮の未知のデータと見立てることで、モデルがどのくらい未知のデータを予測できているのかを評価します。
データの分割は、訓練データ:テストデータが70:30や80:20が一般的です。
過学習かどうかの判断は、訓練データとテストデータのそれぞれに対してどのくらい予測精度があるのかを比較することで行います。
評価には機械学習で良く用いられる評価指標を用います。
評価指標について詳しく知りたい方は『機械学習の評価指標はどう選ぶ?回帰、分類の評価指標をわかりやすく解説!』の記事をご参照ください。

ホールドアウト法はシンプルな手法のため、プログラミングによる実装も簡単です。
ですが、分割方法によっては評価の結果が大きく変わってしまうことがあるため、次に解説する交差検証法と組み合わせることをおすすめします。
2. 交差検証法(Cross-Validation)を行う

交差検証法(Cross-Validation)とは、データを何等分かに分割し、それぞれを訓練データとテストデータに交代させながら過学習かどうかを判断する方法です。
ホールドアウト法を複数回行うことで、より平均的な評価を得られるため、多くの予測モデルで使われている過学習の判断方法になります。
一般的な交差検証法としてk分割交差検証があります。
kは分割数を表していて、例えばk=5の場合は5分割して、4つを訓練データ、1つをテストデータにして、全ての分割にテストデータの役割が回ってくるように5回評価を行います。
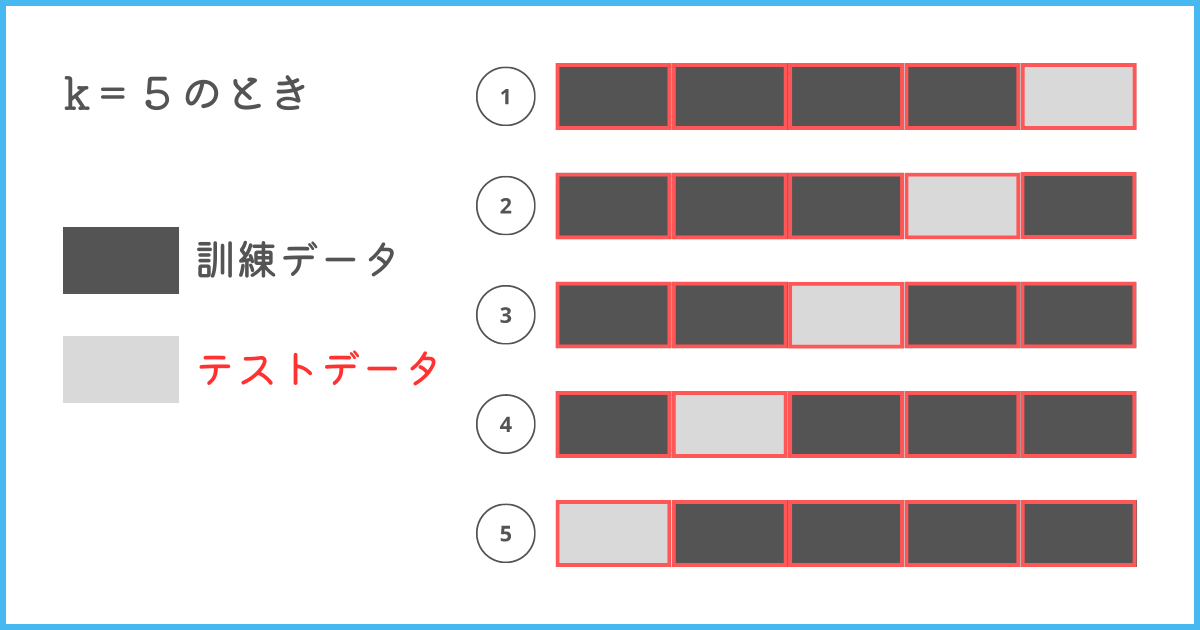
図に表すと上の画像のようなイメージとなります。
他にもデータが少ない場合に用いるLeave-One-Out交差検証(LOOCV)などさまざまな手法があります。
交差検証法のやり方や概要について詳しく知りたい方は『交差検証法とは?種類やPythonの実装・ホールドアウト法との違いまでわかりやすく解説』の記事をご参照ください。

3. 学習曲線を見て判断する
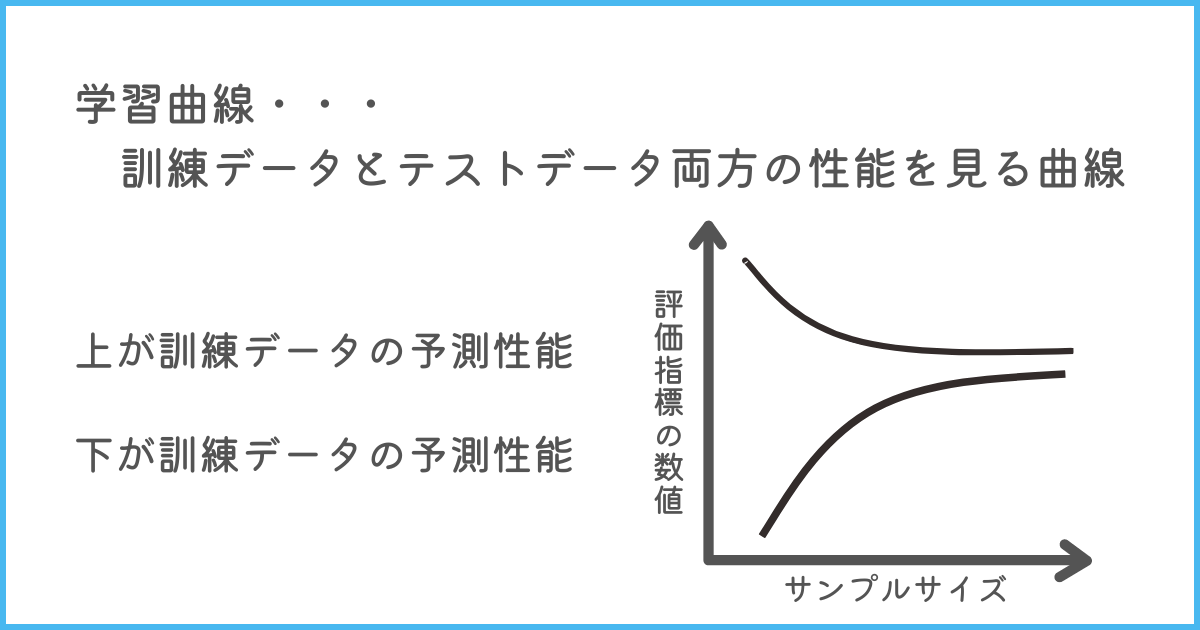
過学習の判断方法として、学習曲線を用いる方法があります。
学習曲線とは、学習に用いるデータ(訓練データ)の数の推移を横軸、評価指標を縦軸に取り、訓練データとテストデータの両方の性能の変化を表したグラフです。
最適な状態の場合、訓練データでもテストデータでも同じくらいの評価指標の値になるため、2つの曲線が収束する(近づく)特徴があります。
実際にグラフでは以下のようになります。
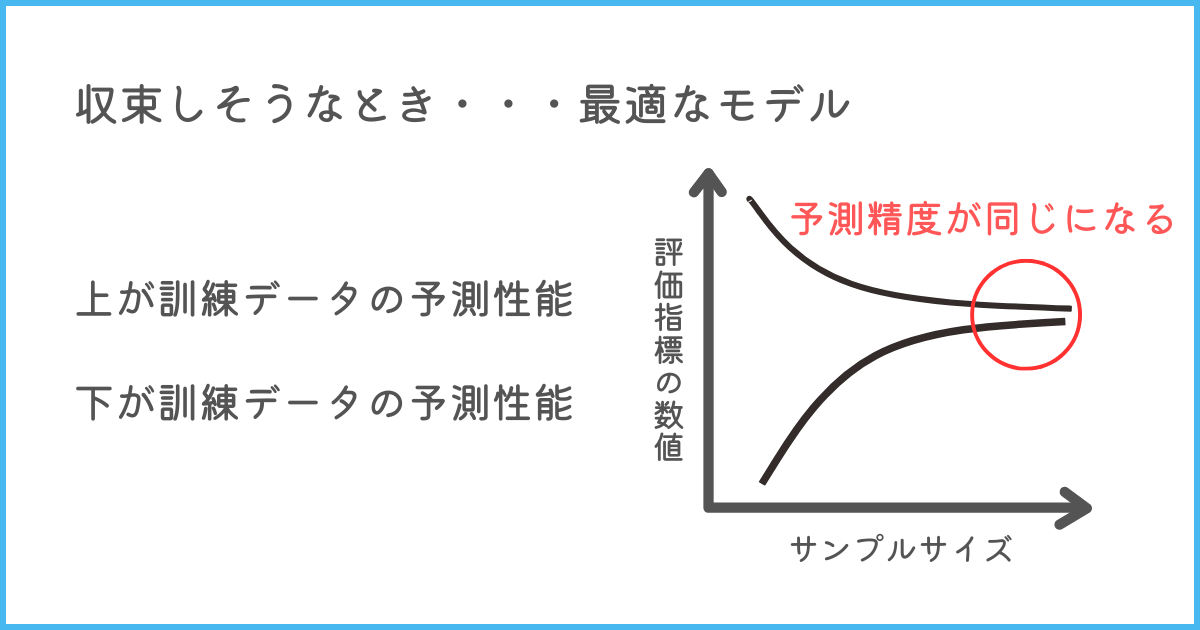
しかし、過学習している場合、学習データの評価指標の値が大きく、テストデータの評価指標の値は低い状態を維持することで、収束しなくなります。
こちらも図に表してみます。
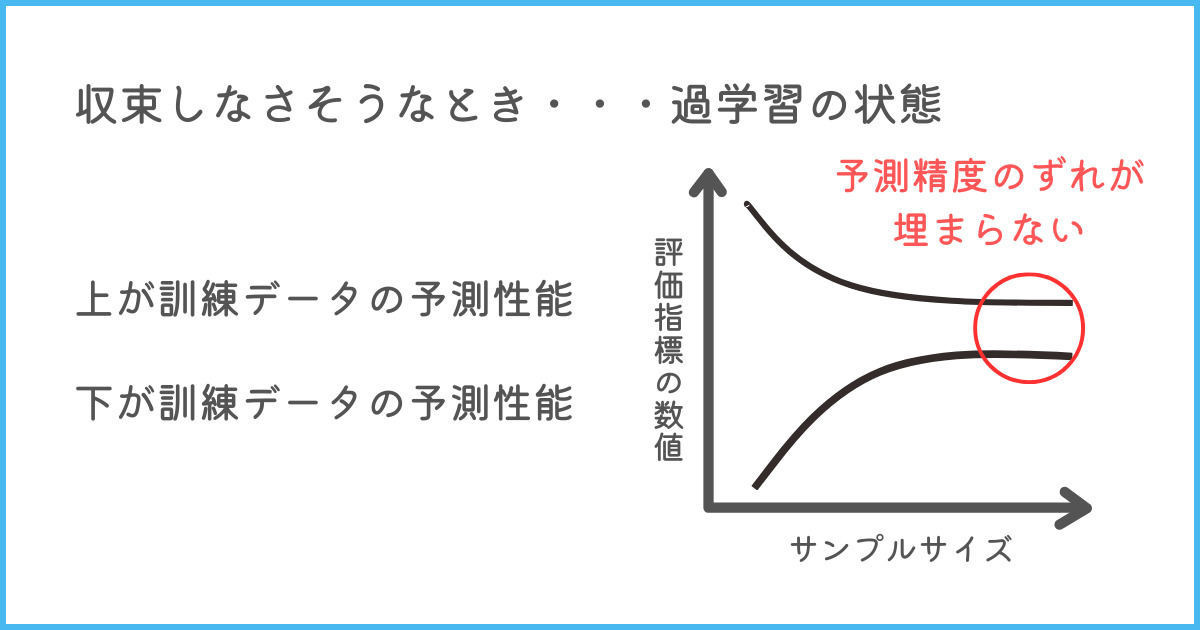
このように、曲線が収束するかどうかをグラフで見ることで過学習かどうかを判断できます。
過学習を防ぐ3つの対策方法

過学習を防げる対策方法は以下の3つです。
- データを増やす
- 正則化を行う
- アンサンブル学習を行う
過学習はモデルの作成において重大な問題のため、これらの対策を行うことで下げる必要があります。
それぞれ解説していきます。
1. データを増やす
過学習を防ぐためには多くのデータを用意することが重要です。
データが少なければ多様な情報をモデルに学習させられず、過学習になる可能性が高くなります。
より多くのデータをモデルの学習に用い、特定のデータに適合しすぎることがないよう心がけましょう。
また、ただデータを集めるのではなく、多様なデータを集めることを意識してください。
2. 正則化を行う
正則化を行うことで、モデルの複雑さを抑え、より未知のデータにも適合するようにモデルを修正できます。
正則化には以下の2つの種類があります。
- L1正則化:重要なく特徴量の係数を0に近づける
- L2正則化:値の大きい特徴量の係数を小さくする
それぞれが過学習を防ぐ効果があり、L1正則化は特徴量を選択できる効果を持ちます。
更に詳しく正則化について知りたい方は、『機械学習の正則化とは?L1正則化とL2正則化やPythonでの実装までカンタン解説!』の記事をご参照ください。

正則化は過学習を防ぐ方法として有名なので、理解しておくことをおすすめします。
3. アンサンブル学習を行う
アンサンブル学習とは複数のモデルを組み合わせて利用する手法で、過学習を防ぐ方法として重要です。
アンサンブル学習の中でもバギングが過学習を防ぐ方法として有名です。
バギングは、複数のモデルでデータを学習しそれらを平均したり多数決を取ることで予測結果を得ます。
複数のモデルを組み合わせて予測結果を得ることで、過学習を防げるだけでなく安定した予測結果となります。
アンサンブル学習について詳しく知りたい方は『アンサンブル学習とは?3つの種類や注意点までわかりやすく解説』の記事をご参照ください。

アンサンブル学習はモデルを作る上で重要な手法のため、正則化と合わせて覚えておきましょう。
まとめ
過学習はモデルを作る上で最も注意しなければなりません。
訓練データに過剰に適合してしまうことで、未知のデータに対する予測精度が低くなり、モデルが使い物にならなくなってしまいます。
過学習が起こる原因は以下の3つです。
- データが不足している
- データが偏っている
- モデルが複雑になっている
データの不足や偏りなど、良くないデータを使用してしまうと過学習になる可能性が高くなります。
また、予測精度を上げたいからとモデルを複雑にすることも注意して行いましょう。
以下の3つの方法で過学習かどうかを判断できます。
- ホールドアウト法
- 交差検証法
- 学習曲線の可視化
訓練データとテストデータに分割することで、未知のデータをどのくらい予測できているのかをテストデータで確認できます。
また、学習曲線で訓練データとテストデータの予測性能の差を見ることで、同じような精度が出ていない場合、過学習だと見抜けます。
もし、過学習になってしまったら、以下の3つの対策を検討しましょう。
- データを増やす
- 正則化を行う
- アンサンブル学習を行う
これらの対策をすることで、未知のデータに対しても安定した予測精度を保てます。
しかし、対策しすぎることで予測精度が出なくなる可能性もあるため、注意してください。
過学習はモデルの作成にとって重要な問題ですが、落ち着いて対処すれば対策できます。
この記事を活用して良いモデルを作成しましょう
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}