


- 損失関数って結局なに?
- 損失関数の微分ができない...
- 損失関数を最小化ってどうやる?
こんな悩みを解決できる記事になっています!
なぜなら、私が「損失関数」の勉強中に分からなかったことも、すべて網羅して解説しているからです。
本記事の信頼性
この記事を読み終えることで、『損失関数』を理解できるだけでなく、『損失関数』を数学的に説明できるようになるでしょう。
記事の前半では『損失関数とは何なのか』を解説しつつ、記事の後半では『損失関数の計算・最適化方法』を分かりやすくお伝えします。
月額980円で学べる!

データサイエンスの復習は完ぺきにできていますか?
データサイエンスは勉強する範囲が膨大で、復習に手が回りませんよね。
そんなあなたにおすすめなのが、たった月額980円でサクッと学べる『スタアカ』

数分の動画でビジネスへの活用法も含めて、サクッとデータサイエンスを復習可能。
『何冊も参考書を往復して復習する苦労』とはおさらばです!
サブスクなのでいつでも解約OK。手軽に始めてみませんか?
\月額980円から/
講座が毎月追加されるので今後値上がりする可能性大、今買わなきゃ損するかも!
それでは本編です!
損失関数(Loss)とは
とはのアイキャッチ画像.png)
損失関数とは機械学習のモデルで算出した予測値と実際の値との誤差を表す式です。
作成したモデルがどの程度の精度があるかを確認することに損失関数が用いられます。
代表的な損失関数は以下の2つで、それぞれの関数が回帰と分類の損失関数です。
- 回帰:二乗和誤差(SSE)
- 分類:交差エントロピー(Cross-Entropy)
損失関数を理解していないと、せっかくモデルを作成したのに精度が分からない...となってしまいます。
自分が作成したモデルの精度を正しく求められるように、損失関数を理解しましょう。
それぞれの損失関数を簡単に解説していきます。
回帰:二乗和誤差(SSE)
二乗和誤差(Sum of Squared Errors)は予測値と正解値の差を2乗して合計する損失関数です。
二乗和誤差は回帰問題を解くモデルの損失関数として利用されます。
数式で表すと、以下の通りです。(実際の値:\( y \)、予測値:\( \hat{y} \))
\[
\text{SSE} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
\]
なんで2乗するの?
2乗しているのは、予測値と実際の値の引き算で必ず発生するマイナスの値を、プラスにして誤差として足し合わせるためです。
しかし、2乗することで大きい誤差(外れ値)があった場合に影響を受けてしまうことに注意しましょう。
そのため、あらかじめ外れ値を除外して、二乗和誤差を計算することをおすすめします。
分類:交差エントロピー(Cross-Entropy)
交差エントロピーは予測値の対数(log)に正解値を掛け、それを合計したものに-1を掛けた関数です。
分類問題を解くモデルの損失関数として交差エントロピーが利用されます。
あんまりイメージが湧かない...
数式に表すと以下のように書けます。
\[
H(y, \hat{y}) = -\sum_{i} y_i \log_2(\hat{y_i})
\]
交差エントロピーでは、予測値が確率で表されるため0から1の範囲に収まります。
今回は例題として、交差エントロピーのΣ内の計算式を1回分解いてみましょう。
例えば、りんご・みかん・なしの3種類を見分ける分類問題で、なしが答えであるとき、
- 実際の値\( y_i \):
[0, 0, 1] - 予測の値\( \hat{y_i} \):
[0.1, 0.2, 0.7]
のように値が当てはまり、それぞれの項目について計算するイメージです。
0から1の範囲で対数(log)を取ると、必ずマイナスの値になることから、最後に-1がかけられます。
じゃあそもそも対数を取るのはなんで?
対数を取るのは、予測が間違っている場合に誤差を大きくするためです!
先ほど挙げた例題から分かるように、実際の値が1になる場合は正解の1つしかありません。
実際に1回の交差エントロピーを計算してみましょう。
スマホの方はスクロールできます!
\begin{split}
H(y_i, \hat{y_i}) &= - y_i \log_2(\hat{y_i}) \\
&= -0\log_2(0.1)-0\log_2(0.2)-1\log_2(0.7)\\
&= -1\log_2(0.7)\end{split}
以上の式のように、実際に1回の交差エントロピーが計算されるのは、係数の\( y_i \)が1である時だけなのです。
もし、正解なのに予測が間違っていたら、誤差としては大きくする必要がありますよね。
対数を用いると普通に計算するより誤差が大きくなるの?
対数は0付近で一気にマイナスの値が大きくなる性質があります!
実際に対数(log)のグラフを確認してみましょう。
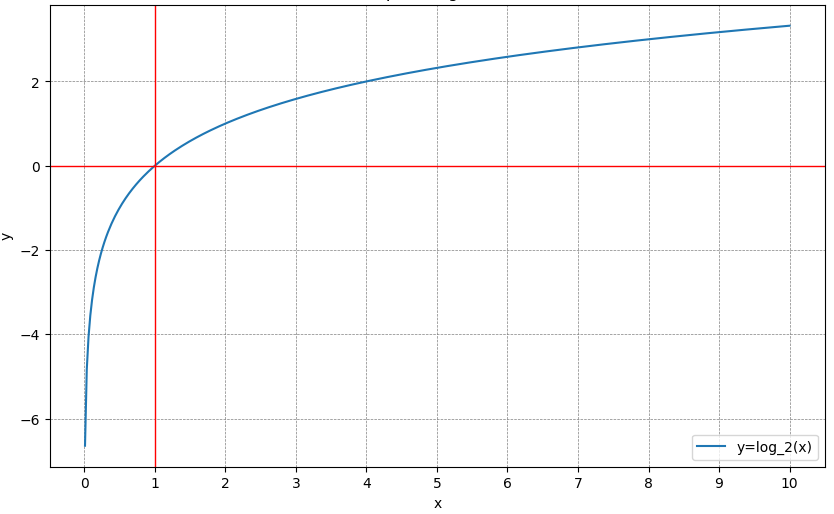
x(今回の予測値)が0に近づくほど、マイナスの値が増加しているのが分かりますね。
対数を取ると予測が間違っている時の誤差を大きく出来るので、交差エントロピーの式に用いられているのです。
交差エントロピーのことを詳しく知りたい方は、『交差エントロピーとは?誤差の計算からPythonでの実装まで解説』の記事をご参照ください。

2つの損失関数の微分の方法を解説

この章では、二乗和誤差と交差エントロピーの2つの損失関数の微分を解説します。
- 二乗和誤差の微分
- 交差エントロピーの微分
それぞれ、一回分の誤差の微分をしていることに注意してください。
それでは、解説していきます。
二乗和誤差の微分
二乗和誤差の各項(足し合わせる前)は以下の式で書けます。
\[
\frac{d}{d\hat{y}_i} \left( (y_i - \hat{y}_i)^2 \right) = -2(y_i - \hat{y}_i)
\]
二乗和誤差を微分することで、損失を最小にできる勾配(傾き)を求められます。
途中式を省かずに微分を計算すると以下の通りです。
\begin{split}
\frac{d}{d\hat{y}_i} \left( (y_i - \hat{y}_i)^2 \right) &= \frac{d}{d\hat{y}_i} \left(y_i^2 - 2y_i\hat{y}_i - \hat{y}_i^2\right) \\
&= - 2y_i - 2\hat{y}_i \\
&= -2(y_i - \hat{y}_i)
\end{split}
後で説明する勾配降下法という損失関数の最適化手法で微分した式が用いられます。
実際はプログラミングで自動的に計算されますが、押さえておいて損はありません。
交差エントロピーの微分
今回は、交差エントロピーがよく用いられる2クラスの分類問題の式の微分を解説します。
まず、多クラスと違い、2クラスだけに用いられる交差エントロピーの式が以下です。
スマホの方はスクロールできます!
\[ H(y, \hat{y}) = -y\log_2(\hat{y})-(1-y)\log(1 - \hat{y}) \]
この時の\( y \)と\( \hat{y} \)はベクトルではなく確率の数値が入っています。
なんで2クラスはこう書けるの?
詳しくは『交差エントロピー』の記事で解説しています!
交差エントロピーの微分の式は以下のように書けます。
\[
\frac{d}{d \hat{y_i}} H(y, \hat{y}) = -\frac{y}{\hat{y}} + \frac{1 - y}{1 - \hat{y}}
\]
この交差エントロピーの微分の式は、ロジスティック回帰分析などでも用いられる重要な式です。
対数(log)の微分は\( f'(\log_2(a)) = \frac{1}{a} \)となることを押さえておくとよいでしょう。
今回は、つまづきやすいポイントである\( -(1-y)\log(1 - \hat{y}) \)の微分に絞って解説します。
logの中身がややこしくてどうしたらいいか分からない...
微分を分割して行う連鎖律を活用して微分します!
微分を分割する連鎖律を用いるために、\( 1 - \hat{y_i} = a \)と置きます。
実際に分割して途中式を省かず計算してみましょう。
スマホの方はスクロールできます!
\begin{split}
\frac{d}{d\hat{y}} (-(1-y)\log(1 - \hat{y})) &= - \frac{d((1-y)\log(a))}{da} \cdot \frac{da(=1 - \hat{y})}{d\hat{y}} \\
&= - \frac{1-y}{a} \cdot -1 \\
&= \frac{1 - y}{1 - \hat{y}} (\unicode{x2235} a = 1 - \hat{y})
\end{split}
以上のように、微分を分割することで、つまづくことなく計算できます。
連鎖律は難しい微分でよく使うので覚えておくとよいでしょう!
損失関数をPythonで計算する方法

損失関数は機械学習のモデルを最適化するために用いられることが多いです。
そこで、今回は損失関数の計算方法についてご紹介します。
- 二乗和誤差をPythonで実装
- 交差エントロピーをPythonで実装
- 【例】線形回帰の誤差を二乗和誤差で求める
以上の流れで、それぞれ解説していきます。
二乗和誤差をPythonで実装
二乗和誤差はPythonの機械学習ライブラリであるsklearnを使うと、簡単に計算できます。
以下が、ライブラリのインポートから二乗和誤差の計算までを行うコードです。
from sklearn.metrics import mean_squared_error
# 実際の値と予測値
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
# 二乗和誤差を計算
sse = mean_squared_error(y_true, y_pred) * len(y_true)
print(f"SSE: {sse}")このコードは、mean_squared_error関数にデータの数を掛けて、二乗和誤差を計算しています。
y_trueは実際の値、y_predは予測値で、値のリストを関数に渡すだけで、二乗和誤差が自動で計算されるのです。
二乗和誤差はデータの数に誤差の大きさが依存してしまうので、主に平均二乗誤差がモデルの評価として使われます。
交差エントロピーをPythonで実装
次に、交差エントロピーをPythonで計算する方法です。
交差エントロピーの計算にもsklearnライブラリが便利です。
以下がサンプルコードになります。
from sklearn.metrics import log_loss
import numpy as np
# 実際の値と予測値
y_true = np.array([0, 0, 1])
y_pred = np.array([0.1, 0.2, 0.7])
# 交差エントロピーを計算
loss = log_loss(y_true, y_pred)
print(f"Log Loss: {loss}")このコードでは、log_loss関数を使って交差エントロピーを計算しています。
y_trueは実際のクラスラベル(0または1)、y_predはそのクラスに属する確率です。
log_loss関数もデータの数で割っていることがあるので注意しましょう。
【例】線形回帰の誤差を二乗和誤差で求める
それでは、実際に線形回帰問題の誤差を二乗和誤差で計算してみましょう。
以下が、線形回帰のモデルを訓練し、二乗和誤差で評価、グラフを算出するPythonコードの例です。
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# サンプルデータ生成(線形関係を持つ)
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 線形回帰のパラメータを求める(正規方程式を使用)
X_b = np.c_[np.ones((100, 1)), X] # x0=1 を追加
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
# 予測値を計算
y_pred = X_b.dot(theta_best)
# 平均二乗誤差(MSE: Mean Squared Error)を計算
mse = mean_squared_error(y, y_pred)
# 二乗和誤差(SSE: Sum of Squared Errors)を計算(MSE × サンプル数)
sse = mse * len(y)
print(f"平均二乗誤差(MSE): {mse}")
print(f"二乗和誤差(SSE): {sse}")
# プロット
plt.scatter(X, y)
plt.plot(X, y_pred, "r-")
plt.xlabel("X")
plt.ylabel("y")
plt.title("Linear Regression and SSE")
plt.show()
この例では、まずLinearRegressionクラスを使って線形回帰のモデルを訓練しています。
その後、訓練データに対する予測値を求め、mean_squared_error関数のデータの数で掛けて二乗和誤差を計算という流れです。
ぜひ関数を一度実行して、平均二乗誤差と二乗和誤差の値の違いにも注目してみましょう。
損失関数の最小化のための手法

損失の求め方は分かったけど、どうやって最小化するの?
以下で、このような疑問を解決していきます。
損失関数を最小化するには、勾配降下法という手法が用いられます。
- 勾配降下法(Gradient Descent)
- 確率的勾配降下法(SGD)
この記事では、以上の2つの勾配降下法を簡単に解説していきます。
勾配降下法(Gradient Descent)
勾配降下法(Gradient Descent)は、機械学習や最適化問題でよく用いられる手法の一つです。
勾配降下法の目的は、損失関数を最小化するパラメータを見つけたり最適化問題で最大化したりすることに用いられます。
勾配が正の場合はパラメータを減らし、勾配が負の場合はパラメータを増やす更新を繰り返して最適化を行うのです。
具体的な更新式は以下になります。
\[
\theta_{\text{new}} = \theta_{\text{old}} - \alpha \cdot \nabla J(\theta_{\text{old}})
\]
ここで、\( \theta_{\text{old}} \)はパラメータ、αは学習率、\( \nabla J(\theta_{\text{old}}) \)は損失関数の勾配です。
このように、勾配降下法は、損失関数を最小化する最適なパラメータを効率的に探索する手法として広く用いられています。
確率的勾配降下法(SGD)
確率的勾配降下法(SGD)は、全データを使わずにランダムに選んだ一部のデータで勾配を計算する勾配降下法の1つです。
全データでないことで、計算速度が速くなる一方、最適解に収束する過程が不安定になる可能性があります。
具体的な更新式は勾配降下法と同じですが、勾配を計算する際に使用するデータが異なることを覚えておきましょう。
まとめ
損失関数とは機械学習のモデルで算出した予測値と実際の値との誤差を表す式です。
作成したモデルがどの程度の精度があるかを確認することに損失関数が用いられることを覚えておきましょう。
損失関数は以下の2つが代表的な例です。
- 回帰:二乗和誤差(SSE)
- 分類:交差エントロピー(Cross-Entropy)
機械学習では必ずと言っていいほど出てくる損失関数ですので、必ず理解しておくことをおすすめします。
そして、損失関数を最適化するためには、以下の2つの手法を用いることも併せて押さえてください。
- 勾配降下法(Gradient Descent)
- 確率的勾配降下法(SGD)
せっかく損失を計算できるようになったのに、最適化できないとなれば意味がありません。
損失関数を正しく理解して、より高精度なモデルを作成できるようになりましょう!
- 機械学習の勉強がなかなか上手く進まない...
- 勉強していても全体像が見えてこない...
- 本当にデータサイエンティストになれるのかな...
と不安に感じてはいませんか?
そんな悩みをまるっと解決してくれるサービスが『スタアカ』です。
僕も利用している『スタアカ』のライトプランは月額980円で動画見放題でコスパ最強です。
「勉強の道しるべが欲しい!」「学習を効率的に進めたい」という方にはこの上ないサブスクです。
データサイエンスを学びたい方に最強のサブスク『スタアカ』を気軽に始めてみませんか?
\月額たった980円!/
講座が毎月追加されるので今後値上がりする可能性大、今が買いどき!
「ちょっとでも興味がある」という方は、受講した感想も載せている記事もあわせてどうぞ。







{kind=link}